Basketball has been heavy on mind lately. One reason being the All the Smoke podcast that I listen to with Matt Barnes and Stephen Jackson every week. I’ve been listening to the podcast since day one. Another reason has been the recent passing of Kobe Bryant, his daughter Gianna and the seven other lives that were taken in that helicopter accident. When I think of Kobe, I think about my brother and the kids I went to school with. They would shout ‘KOBE’ anytime they threw something.
Because of people like my brother, like those kids I went to school with, I decided to go with a basketball theme with this post. I wanted to shed light on some of the players that Kobe inspired and some that maybe inspired him. The data set that I will use for this blog post was posted on Kaggle by Jason Baruch. Baruch created the NBA Player of the Week data set that analyzes player of the week data from 1979-80 season to the present. I decided to download the csv and play around a bit. With that said, let’s get into data frames in R.
Data frames are a list of vectors of equal length. They can contain multiple data types and they are probably the most common data structure in R. Not only did I learn about data frames but I learned about some R packages that makes doing data science with data frames efficient.
Installing and Loading Packages
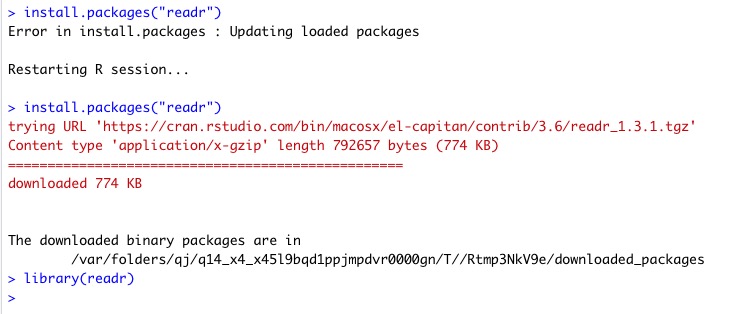
The first thing I did as part of the DataQuest lesson was to install the readr package, which is part of the tidyverse. Readr is designed to improve data science workflow. DataQuest gives me a few ways that readr does this:
- Speed: Importing larger data files with readr functions is generally faster than using base R functions. By the way, base R is just the basic software that comes with the R programming language.
- Code reproducibility: While base R function behavior depends in part on your operating system and environment variables, this is not the case for readr. When you use readr to import files, code that works on your computer will work on someone else’s.
- Consistency: The readr package shares a common syntax and design philosophy with other tidyverse packages that we’ll introduce in upcoming courses.
After installing readr, I loaded the package using the library function.
Importing Data with R
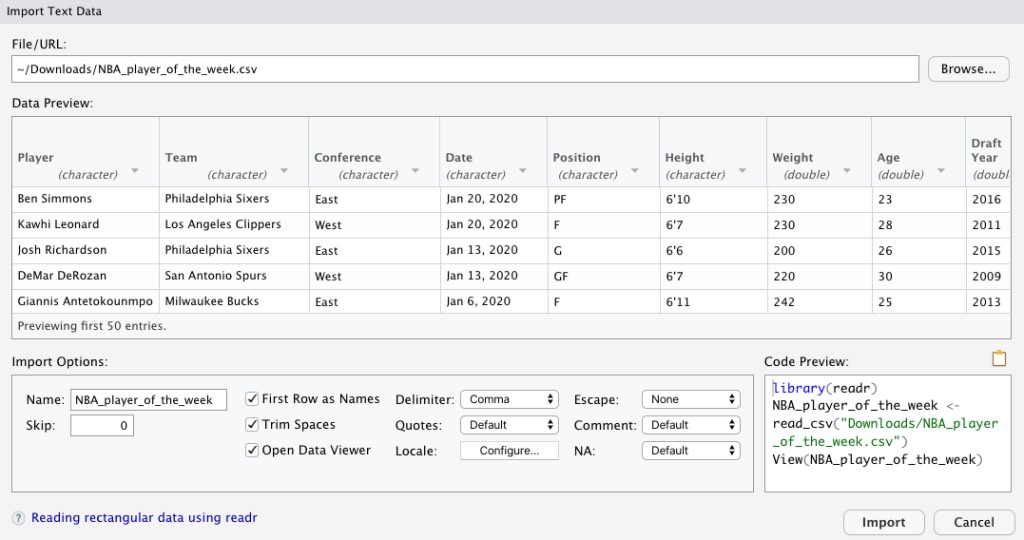
RStudio (the IDE I’ve been using in my posts) has an option to import data. To do this I went to File -> Import Dataset -> From Text(readr). This leads to a screen that prompts me type a file name or URL. However, I decided to click on Browse which leads me to import a document. When I imported my csv that I downloaded from Kaggle, this is what I get:
After I click import, my csv file is opened like this.
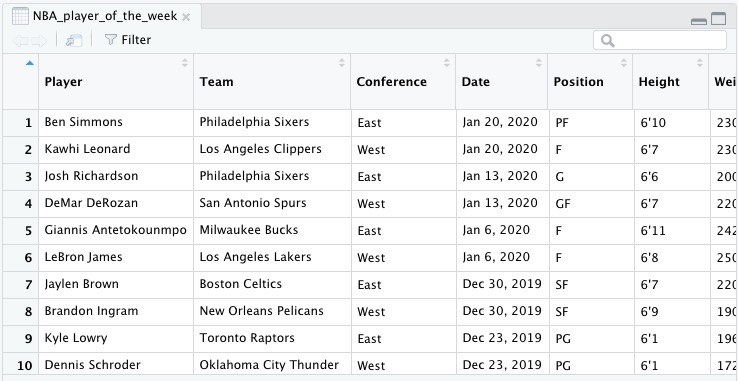
Note: The tidyverse is a collection of packages designed to make using R for data science more effective. In addition to readr, tidyverse includes dplyr which will be discussed later. Instead of installing each package, I installed tidyverse just as I did with readr example in the above screenshots.
View(NBA_player_of_the_week)
Tibbles
To make the data easier to work with, I decided to get my data frame into a tibble. A tibble is the same as a data frame in base R. DataQuest mentions that they are two-dimensional data structures that store data of multiple types. They also have very important advantages: clarity, consistency and printing. You can type the name of a tibble and R will only print the first 10 rows.
tibble::as_tibble(NBA_player_of_the_week)
# A tibble: 1,334 x 17
Player Team Conference Date Position Height Weight Age
<chr> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl>
1 Ben S… Phil… East 20-J… PF 6'10 230 23
2 Kawhi… Los … West 20-J… F 6'7 230 28
3 Josh … Phil… East 13-J… G 6'6 200 26
4 DeMar… San … West 13-J… GF 6'7 220 30
5 Giann… Milw… East 6-Ja… F 6'11 242 25
6 LeBro… Los … West 6-Ja… F 6'8 250 35
7 Jayle… Bost… East 30-D… SF 6'7 220 23
8 Brand… New … West 30-D… SF 6'9 190 22
9 Kyle … Toro… East 23-D… PG 6'1 196 33
10 Denni… Okla… West 23-D… PG 6'1 172 26
# … with 1,324 more rows, and 9 more variables: Draft_Year <dbl>,
# Seasons_in_league <dbl>, Season <chr>, Season_short <dbl>,
# Pre_draft_Team <chr>, Real_value <dbl>, Height_CM <dbl>,
# Weight_KG <dbl>, Last_Season <dbl>Indexing Data Frames
For data frames, I can use indexing to return a specific, row, column or value. It’s pretty similar to indexing matrices. If I wanted to index the column “Team”, I could do this in a couple of ways:
By position :
NBA_player_of_the_week[, 2]
# A tibble: 1,334 x 1
Team
<chr>
1 Philadelphia Sixers
2 Los Angeles Clippers
3 Philadelphia Sixers
4 San Antonio Spurs
5 Milwaukee Bucks
6 Los Angeles Lakers
7 Boston Celtics
8 New Orleans Pelicans
9 Toronto Raptors
10 Oklahoma City Thunder
# … with 1,324 more rowsBy column name:
NBA_player_of_the_week[, "Team"]
# A tibble: 1,334 x 1
Team
<chr>
1 Philadelphia Sixers
2 Los Angeles Clippers
3 Philadelphia Sixers
4 San Antonio Spurs
5 Milwaukee Bucks
6 Los Angeles Lakers
7 Boston Celtics
8 New Orleans Pelicans
9 Toronto Raptors
10 Oklahoma City Thunder
# … with 1,324 more rowsDataQuest also mentioned that I could use a $ symbol to specify a column though when I tried this method R printed 1000 rows of data.
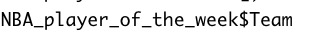
Here are some more examples of indexing data frames:
NBA_player_of_the_week$Team[2]
[1] "Los Angeles Clippers"NBA_player_of_the_week[6,2]
# A tibble: 1 x 1
Team
<chr>
1 Los Angeles LakersNBA_player_of_the_week[6, ]
# A tibble: 1 x 17
Player Team Conference Date Position Height Weight Age
<chr> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl>
1 LeBro… Los … West 6-Ja… F 6'8 250 35
# … with 9 more variables: Draft_Year <dbl>, Seasons_in_league <dbl>,
# Season <chr>, Season_short <dbl>, Pre_draft_Team <chr>,
# Real_value <dbl>, Height_CM <dbl>, Weight_KG <dbl>,
# Last_Season <dbl># A tibble: 7 x 2
Player Pre_draft_Team
<chr> <chr>
1 Kawhi Leonard San Diego State
2 Josh Richardson Tennessee
3 DeMar DeRozan USC
4 Giannis Antetokounmpo Filathlitikos Div II Greece (Greece)
5 LeBron James St. Vincent St. Mary High School (Ohio)
6 Jaylen Brown California
7 Brandon Ingram Duke Working With Data Frame Columns
I could simplify my data frame to contain only variables(the column names) that are relevant for my data analysis.
For example, I want to create a new data frame that includes the names of the players, their teams, characteristics(height, weight, age), draft year and how many seasons they’ve played in the league. I would use dplyr, a tidyverse package designed for analyzing data in data frames.
To use this package, I would install and load it just as I did with the readr package. The dplyr function select() allows me to create a new data frame with only the columns containing the variables I want to use for my analysis. I realized that I already have tidyverse installed so I loaded that before creating this new data frame.
NBA_player_of_the_week_select <- NBA_player_of_the_week %>% select(Player, Team, Position, Height, Weight, Age, Draft_Year, Seasons_in_league)
NBA_player_of_the_week_select
# A tibble: 1,334 x 8
Player Team Position Height Weight Age Draft_Year
<chr> <chr> <chr> <chr> <dbl> <dbl> <dbl>
1 Ben S… Phil… PF 6'10 230 23 2016
2 Kawhi… Los … F 6'7 230 28 2011
3 Josh … Phil… G 6'6 200 26 2015
4 DeMar… San … GF 6'7 220 30 2009
5 Giann… Milw… F 6'11 242 25 2013
6 LeBro… Los … F 6'8 250 35 2003
7 Jayle… Bost… SF 6'7 220 23 2016
8 Brand… New … SF 6'9 190 22 2016
9 Kyle … Toro… PG 6'1 196 33 2006
10 Denni… Okla… PG 6'1 172 26 2013
# … with 1,324 more rows, and 1 more variable:
# Seasons_in_league <dbl>I could also create new variables and add them to my data frame as columns using another dplyr function called mutate().
NBA_player_of_the_week_mutate <- NBA_player_of_the_week %>% mutate(Draft_Age = Age-(2020-Draft_Year))
NBA_player_of_the_week_mutate
# A tibble: 1,334 x 18
Player Team Conference Date Position Height Weight Age
<chr> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl>
1 Ben S… Phil… East 20-J… PF 6'10 230 23
2 Kawhi… Los … West 20-J… F 6'7 230 28
3 Josh … Phil… East 13-J… G 6'6 200 26
4 DeMar… San … West 13-J… GF 6'7 220 30
5 Giann… Milw… East 6-Ja… F 6'11 242 25
6 LeBro… Los … West 6-Ja… F 6'8 250 35
7 Jayle… Bost… East 30-D… SF 6'7 220 23
8 Brand… New … West 30-D… SF 6'9 190 22
9 Kyle … Toro… East 23-D… PG 6'1 196 33
10 Denni… Okla… West 23-D… PG 6'1 172 26
# … with 1,324 more rows, and 10 more variables: Draft_Year <dbl>,
# Seasons_in_league <dbl>, Season <chr>, Season_short <dbl>,
# Pre_draft_Team <chr>, Real_value <dbl>, Height_CM <dbl>,
# Weight_KG <dbl>, Last_Season <dbl>, Draft_Age <dbl>As you can see, a new column called Draft_Age was added to my table.

Filtering A Data Frame
Using the filter() function, I could filter a data frame either using a single condition or multiple conditions. This is where the comparison operators come in.
Single Conditions
I could simplify my data frame further by filtering. I would use another dplyr function, filter() to specify conditions that variables must meet in order to be retained in my data frame.
If I want to retain data on players who play for the Eastern Conference, I would type this:
NBA_player_of_the_week_east <- NBA_player_of_the_week %>% filter(Conference == "East")
NBA_player_of_the_week_east
# A tibble: 417 x 17
Player Team Conference Date Position Height Weight Age
<chr> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl>
1 Ben S… Phil… East 20-J… PF 6'10 230 23
2 Josh … Phil… East 13-J… G 6'6 200 26
3 Giann… Milw… East 6-Ja… F 6'11 242 25
4 Jayle… Bost… East 30-D… SF 6'7 220 23
5 Kyle … Toro… East 23-D… PG 6'1 196 33
6 Bam A… Miam… East 16-D… C 6'10 255 22
7 Jimmy… Miam… East 9-De… GF 6'8 232 30
8 Giann… Milw… East 2-De… F 6'11 242 25
9 Spenc… Broo… East 25-N… PG 6'6 210 26
10 Nikol… Orla… East 18-N… PF 7'0 260 29
# … with 407 more rows, and 9 more variables: Draft_Year <dbl>,
# Seasons_in_league <dbl>, Season <chr>, Season_short <dbl>,
# Pre_draft_Team <chr>, Real_value <dbl>, Height_CM <dbl>,
# Weight_KG <dbl>, Last_Season <dbl>Let’s say I wanted to retain data on players whose weight is greater than 200 pounds. I would write this:
NBA_player_of_the_week_weight <- NBA_player_of_the_week %>% filter(Weight > 200)
NBA_player_of_the_week_weight
# A tibble: 1,004 x 17
Player Team Conference Date Position Height Weight Age
<chr> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl>
1 Ben S… Phil… East 20-J… PF 6'10 230 23
2 Kawhi… Los … West 20-J… F 6'7 230 28
3 DeMar… San … West 13-J… GF 6'7 220 30
4 Giann… Milw… East 6-Ja… F 6'11 242 25
5 LeBro… Los … West 6-Ja… F 6'8 250 35
6 Jayle… Bost… East 30-D… SF 6'7 220 23
7 Bam A… Miam… East 16-D… C 6'10 255 22
8 LeBro… Los … West 16-D… F 6'8 250 35
9 Jimmy… Miam… East 9-De… GF 6'8 232 30
10 Antho… Los … West 9-De… PF 6'10 253 26
# … with 994 more rows, and 9 more variables: Draft_Year <dbl>,
# Seasons_in_league <dbl>, Season <chr>, Season_short <dbl>,
# Pre_draft_Team <chr>, Real_value <dbl>, Height_CM <dbl>,
# Weight_KG <dbl>, Last_Season <dbl>Multiple Conditions
I was introduced to two new operators: The & operator specifies that both criteria in an expression must be met. The | operator specifies that at least one of the criteria in the expression must be met.
NBA_player_of_the_week_stature <- NBA_player_of_the_week %>% filter(Weight > 200 & Height > "6'5")
NBA_player_of_the_week_stature
# A tibble: 684 x 17
Player Team Conference Date Position Height Weight Age
<chr> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl>
1 Kawhi… Los … West 20-J… F 6'7 230 28
2 DeMar… San … West 13-J… GF 6'7 220 30
3 LeBro… Los … West 6-Ja… F 6'8 250 35
4 Jayle… Bost… East 30-D… SF 6'7 220 23
5 LeBro… Los … West 16-D… F 6'8 250 35
6 Jimmy… Miam… East 9-De… GF 6'8 232 30
7 Carme… Port… West 2-De… F 6'8 240 35
8 Spenc… Broo… East 25-N… PG 6'6 210 26
9 Luka … Dall… West 25-N… SF 6'7 218 21
10 Nikol… Orla… East 18-N… PF 7'0 260 29
# … with 674 more rows, and 9 more variables: Draft_Year <dbl>,
# Seasons_in_league <dbl>, Season <chr>, Season_short <dbl>,
# Pre_draft_Team <chr>, Real_value <dbl>, Height_CM <dbl>,
# Weight_KG <dbl>, Last_Season <dbl>NBA_player_of_the_week_draft <- NBA_player_of_the_week %>% filter(Draft_Year > 2014 | Seasons_in_league <= 5)
NBA_player_of_the_week_draft
# A tibble: 692 x 17
Player Team Conference Date Position Height Weight Age
<chr> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl>
1 Ben S… Phil… East 20-J… PF 6'10 230 23
2 Josh … Phil… East 13-J… G 6'6 200 26
3 Jayle… Bost… East 30-D… SF 6'7 220 23
4 Brand… New … West 30-D… SF 6'9 190 22
5 Bam A… Miam… East 16-D… C 6'10 255 22
6 Spenc… Broo… East 25-N… PG 6'6 210 26
7 Luka … Dall… West 25-N… SF 6'7 218 21
8 Pasca… Toro… East 11-N… F 6'9 230 25
9 Trae … Atla… East 28-O… PG 6'2 180 21
10 Karl-… Minn… West 28-O… C 7'0 248 24
# … with 682 more rows, and 9 more variables: Draft_Year <dbl>,
# Seasons_in_league <dbl>, Season <chr>, Season_short <dbl>,
# Pre_draft_Team <chr>, Real_value <dbl>, Height_CM <dbl>,
# Weight_KG <dbl>, Last_Season <dbl>Arranging Data Frames by Variables
Another dplyr function, arrange() allows me to specify a variable I want to use to reorder rows of my data frame. Let’s say that I want to arrange my data so that the players’ draft year is in ascending order. I would type this:
NBA_player_of_the_week_draft_yrs<- NBA_player_of_the_week %>% arrange(Draft_Year)
NBA_player_of_the_week_draft_yrs
# A tibble: 1,334 x 17
Player Team Conference Date Position Height Weight Age
<chr> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl>
1 Rick … Hous… <NA> 10-F… F 6'7 205 35
2 Elvin… Wash… <NA> 9-No… FC 6'9 235 35
3 Karee… Los … <NA> 24-M… C 7'2 225 37
4 Karee… Los … <NA> 8-Ap… C 7'2 225 36
5 Karee… Los … <NA> 12-F… C 7'2 225 36
6 Karee… Los … <NA> 28-F… C 7'2 225 34
7 Karee… Los … <NA> 21-D… C 7'2 225 33
8 Karee… Los … <NA> 17-F… C 7'2 225 32
9 Karee… Los … <NA> 9-De… C 7'2 225 32
10 Tiny … Bost… <NA> 11-J… PG 6'1 150 32
# … with 1,324 more rows, and 9 more variables: Draft_Year <dbl>,
# Seasons_in_league <dbl>, Season <chr>, Season_short <dbl>,
# Pre_draft_Team <chr>, Real_value <dbl>, Height_CM <dbl>,
# Weight_KG <dbl>, Last_Season <dbl>Let’s say I change my mind and I want the players’ draft year to be in descending order. It would look like this:
NBA_player_of_the_week_draft_yr <- NBA_player_of_the_week %>% arrange(desc(Draft_Year))
NBA_player_of_the_week_draft_yr
# A tibble: 1,334 x 17
Player Team Conference Date Position Height Weight Age
<chr> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl>
1 Luka … Dall… West 25-N… SF 6'7 218 21
2 Trae … Atla… East 28-O… PG 6'2 180 21
3 Trae … Atla… East 25-M… PG 6'2 180 20
4 Bam A… Miam… East 16-D… C 6'10 255 22
5 Donov… Utah… West 4-Ma… SG 6'3 215 22
6 Donov… Utah… West 14-J… SG 6'3 215 22
7 Ben S… Phil… East 20-J… PF 6'10 230 23
8 Jayle… Bost… East 30-D… SF 6'7 220 23
9 Brand… New … West 30-D… SF 6'9 190 22
10 Pasca… Toro… East 11-N… F 6'9 230 25
# … with 1,324 more rows, and 9 more variables: Draft_Year <dbl>,
# Seasons_in_league <dbl>, Season <chr>, Season_short <dbl>,
# Pre_draft_Team <chr>, Real_value <dbl>, Height_CM <dbl>,
# Weight_KG <dbl>, Last_Season <dbl>Whew, okay that was a lot! That’s it for data frames! Until next time…